Why SMEs handling PII should run local LLMs, not ChatGPT
Every clinic, law firm, and accounting practice we’ve spoken to in the last six months is using ChatGPT for something. Most of them are also quietly worried about it. They’re right to be. If your business processes personal data, the right answer isn’t a better subscription tier. It’s moving the model onto your own machine.
Key Takeaways
- Cloud AI privacy is contractual. Local LLM privacy is architectural. Architectural always wins.
- A local LLM setup (Ollama + a modern open model) runs fine on a single mid-range workstation in 2026.
- Break-even vs ChatGPT Team for a 10-person SME is under 18 months, then free forever.
- The model is the easy part. The orchestration layer on top is where most projects still fail, and where you should pressure-test any vendor.
- UAE PDPL and KSA PDPL both reward architectural controls more than contractual ones. This is a compliance story, not just a tech one.

What does “local LLM” actually mean in 2026?
A local LLM is a language model that runs entirely on hardware you own, with no API call to any external service. The typical stack is Ollama (the runtime) plus an open-weights model like Qwen, Llama, or Mistral. Everything stays on your LAN: prompts, documents, responses. If you unplug the internet, it keeps working.
This is not a theoretical setup. It runs today on a laptop with 32GB of RAM and a recent GPU. It runs better on a dedicated workstation with 64GB and an RTX-class card. It runs well enough for the tasks SMEs actually need (summarisation, extraction, classification, drafting) on hardware that costs less than a year of cloud AI for a small team.
We’ve got this working on our own machines. Two config changes to block outbound traffic from the Ollama process, verified by disconnecting the internet physically and watching the model keep responding. No degradation, no timeout, no “cannot reach server” error. It just runs.
Why is policy-based privacy weaker than architectural privacy?
Policy-based privacy depends on a long chain of contractual promises. Architectural privacy doesn’t need a chain, because the data can’t physically leave the building. That one-sentence difference is the whole argument.
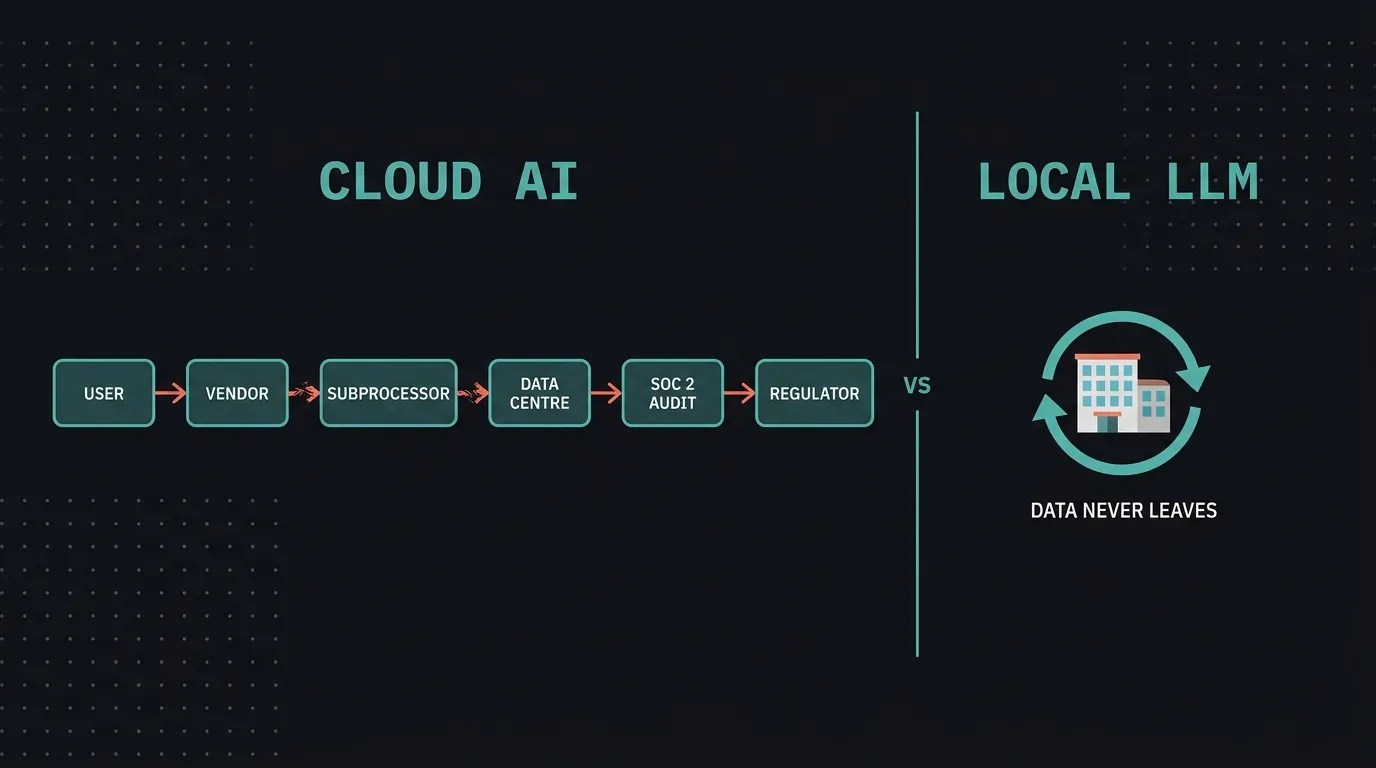
For a cloud AI, the trust chain has six distinct links. Each one is a separate promise you’re relying on:
- You (the user) enter the data. First link, and it depends on your own staff discipline.
- The vendor (OpenAI, Microsoft, Google) receives the data under their terms of service. Second link, the vendor’s contract.
- Subprocessors handle parts of the stack: inference providers, analytics, content-moderation partners. Third link, every vendor the vendor uses.
- The data centre physically stores and processes your data, typically in a US region you don’t control. Fourth link, infrastructure jurisdiction.
- SOC 2 audits exist to prove the above works. Fifth link, annual third-party attestation based on a point-in-time sample.
- Regulators (UAE’s Data Office, KSA’s SDAIA, HIPAA if you’re in healthcare) hold you accountable if any earlier link fails. Sixth link, the one you answer to directly.
When you use ChatGPT, Copilot, or any cloud AI, your privacy runs through every one of those links. Each one is contractual, and you’re trusting that a US-based company will do what it says with your patients’ files.
A local model has no chain. The data doesn’t leave the building because there’s no path out. There’s nothing to audit because there’s nothing to audit. Compliance stops being about proving controls and starts being about demonstrating an architecture.
This matters more in the GCC than elsewhere. UAE’s PDPL (in force January 2025) and KSA’s PDPL (September 2024) both place the burden of proof on the data controller, not the processor. Telling a regulator “the data never left our office” is a much shorter conversation than producing a cross-border transfer impact assessment for a US vendor.
Here’s the part most vendors won’t say out loud. Most AI vendors selling to regulated industries are competing on the quality of their policy documents. We think that’s the wrong axis. The moment a policy is required, you’ve already lost the privacy argument. Architecture is the only honest answer.
What can, and can’t, a local LLM do today?
Modern open models are genuinely good at the tasks most SMEs actually need. Document summarisation, extracting structured data from unstructured text, classifying incoming requests, drafting responses in a consistent tone, answering questions over a private knowledge base: these all work well on a 30-billion-parameter open model. For bilingual Arabic and English work, the latest Qwen and Llama releases are usable.
What they can’t match is the absolute frontier. If your workflow depends on GPT-5-level reasoning or the most recent Claude for long-context synthesis, a local 30B model will feel noticeably weaker. That’s a real tradeoff, and pretending otherwise is how vendors lose trust.
The larger honest gap isn’t the model at all. It’s the orchestration layer. Running a model is easy now. Getting a model to reliably execute a multi-step business workflow, with tools, memory, and human handoffs, is where the real engineering still sits. how AI agents actually work for SMEs
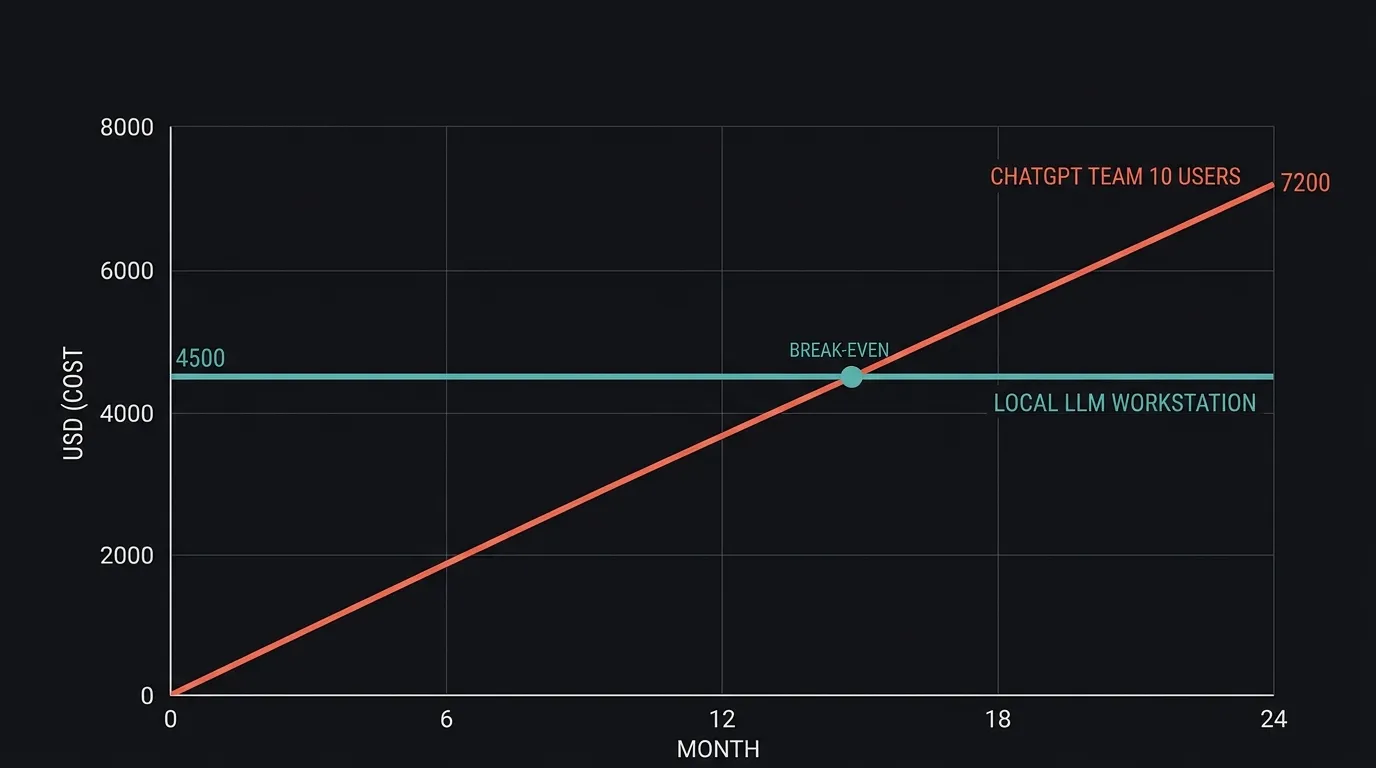
What does it cost compared to ChatGPT Team?
Quick maths for a ten-person team, based on our own pilot setup. ChatGPT Team runs $30 per user per month. Ten users across 24 months comes out to $7,200, rising every time the vendor revises pricing. A local LLM setup capable of serving that team, a decent workstation with a suitable GPU, lands between $3,500 and $5,000 as a one-time cost. Add a few hundred dollars a year for electricity and updates.
Break-even arrives inside 18 months. After that, the cost curve flattens to near zero while the subscription curve keeps climbing. For a business handling PII, the ROI case is almost secondary. The real return is removing a recurring compliance risk from the balance sheet.
Who should actually run a local LLM?
This is not for everyone. If your team uses AI to brainstorm marketing copy and summarise public web pages, ChatGPT is fine. Stay there. The question only matters when the inputs themselves are sensitive.
You should seriously consider local if you fit any of these:
- Medical or dental practices handling patient records, diagnoses, or insurance documents
- Law firms and notaries processing case files, contracts, or privileged correspondence
- Accounting and tax practices working with client financials
- Schools and training centres handling student data under regional education regulations
- HR consultancies processing employee records across multiple clients
- Government contractors or any business with data-residency clauses in their contracts
If you’re in one of those categories and someone on your team is already pasting customer data into a chat window, you have an active problem. The question is whether you solve it with policy or with architecture.
What we’ve learned building this
We’ve been running Ollama internally for several months. Two things surprised us.
First, the developer ergonomics are better than expected. Pairing Ollama with a coding assistant like Cline inside VS Code gives you a private, offline equivalent of GitHub Copilot. For code that touches client data, this alone is worth the setup.
Second, the gap between “model works” and “workflow works” is bigger than we’d assumed. A model that answers questions well isn’t automatically a model that reliably runs a five-step back-office process with external tools. We’re still co-developing that orchestration pattern, and we’d rather tell you that honestly than sell you a finished solution that doesn’t exist yet. When you’re evaluating vendors, the question isn’t “do you have a local LLM?” It’s “what does your agent layer look like, and can I see it run a real workflow?”
How do you start without making a mistake?
Don’t start by buying hardware. Start by listing the three to five workflows where your team is currently pasting sensitive data into a cloud AI. That list is your real requirement document. Most of it will be document summarisation, data extraction, or drafting, which is well within what a local model can do today.
Then run a small pilot. One machine, one team, one workflow. Measure accuracy against your current process. If it holds up, expand. If it doesn’t, you’ve learned cheaply instead of committing to a full deployment. how we run rapid MVP pilots
FAQ
Is a local LLM really as good as ChatGPT for my daily work? For the tasks most SMEs actually run, yes. Summarisation, extraction, drafting, Q&A over private documents, and classification all work well on a modern 30-billion-parameter open model. For absolute-frontier reasoning or the newest coding features, ChatGPT or Claude still lead, and that gap is real.
How much hardware do I really need? A single workstation with 64GB of RAM and a recent RTX-class GPU handles a small team comfortably. A high-end laptop with 32GB can run smaller models for individual use. Total one-time spend sits between $3,500 and $5,000 for a team-capable setup, which pays back against a typical ChatGPT Team subscription inside 18 months.
What happens when the open models get updated? You download the new weights. That’s the whole update process. No breaking API changes, no deprecated endpoints, no pricing surprises. If a new model doesn’t suit your workflow, you keep running the previous one indefinitely.
Does it handle Arabic and other regional languages? The latest Qwen and Llama releases handle Arabic noticeably better than models from even a year ago. For most document work across English and Arabic, results are usable. Highly specialised legal or medical terminology should be tested on your actual content before committing.
Can a local LLM connect to our other systems, or is it stuck in a sandbox? It can connect to anything you want it to, inside your network. The same integration patterns that work for cloud AI, including tool use and retrieval, apply locally. MCP servers and private integration patterns
Bottom line
Cloud AI is a productivity tool. For PII workloads, it’s also a recurring compliance liability. Local LLMs in 2026 are good enough that the tradeoff has flipped: the setup cost is real, but the ongoing risk cost is zero. If your business handles data that shouldn’t leave your walls, the model shouldn’t either.
If you want to pressure-test whether local fits your workflow, book a consultation and we’ll walk through it with you. No pitch, just a look at your actual use cases.